The videos we watch say more about our learning patterns than we usually realize.
I recently worked on a small YouTube history pipeline for myself. The idea was simple:
Can I see what YouTube content I watched over the last year, in a format I can actually analyze?
Not through scraping. Not through browser automation. Not by guessing from recommendations.
Using Google Takeout.
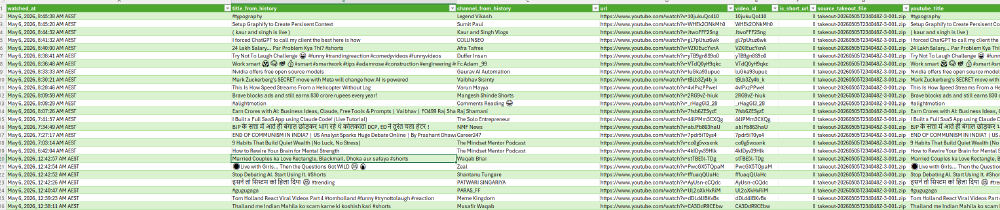
What the Pipeline Does
The pipeline reads YouTube watch history ZIP files directly from Google Takeout, finds watch-history.html, parses watched videos and Shorts, stores the results in SQLite, enriches them with YouTube Data API metadata, and exports everything into an Excel-friendly CSV.
That gives a much clearer view of:
- What topics I kept coming back to
- Which channels shaped my learning
- How much technical content I actually consumed
- What was intentional learning versus casual watching
- Where my attention went over time
The interesting part was not just the data. It was the engineering around a simple personal workflow.
Raw Data Is Not Insight
Google Takeout gives you the raw history, but raw data is not insight.
You still need to:
- Parse inconsistent HTML
- Extract video IDs from different URL formats
- Handle Shorts and
youtu.belinks - Deduplicate records
- Enrich metadata in API batches
- Deal with deleted or private videos
- Export data in a format tools like Excel can open properly
That is usually where small automation projects become useful.
Not because they are complex, but because they turn a manual question into a repeatable workflow.
Local Personal Analytics
For me, this project was also a reminder that personal data can be valuable when it is processed locally and thoughtfully.
Sometimes the best learning dashboard is not another SaaS tool. It is a simple pipeline over your own data.
Repo: github.com/mumehta/yt-history
What personal data source would you like to analyze better if you had a simple local pipeline for it?